
Author: 许宏伟
这篇论文是发表在 ACM MM 2019 上,作者是来自北京大学的博导彭宇新。也是我在valse 2019合肥行听到的一篇论文
相关工作
背景方面,就是围绕着细粒度和单训练样本来做数据增广。只用一个样本进行数据增广,作者也是煞费苦心。
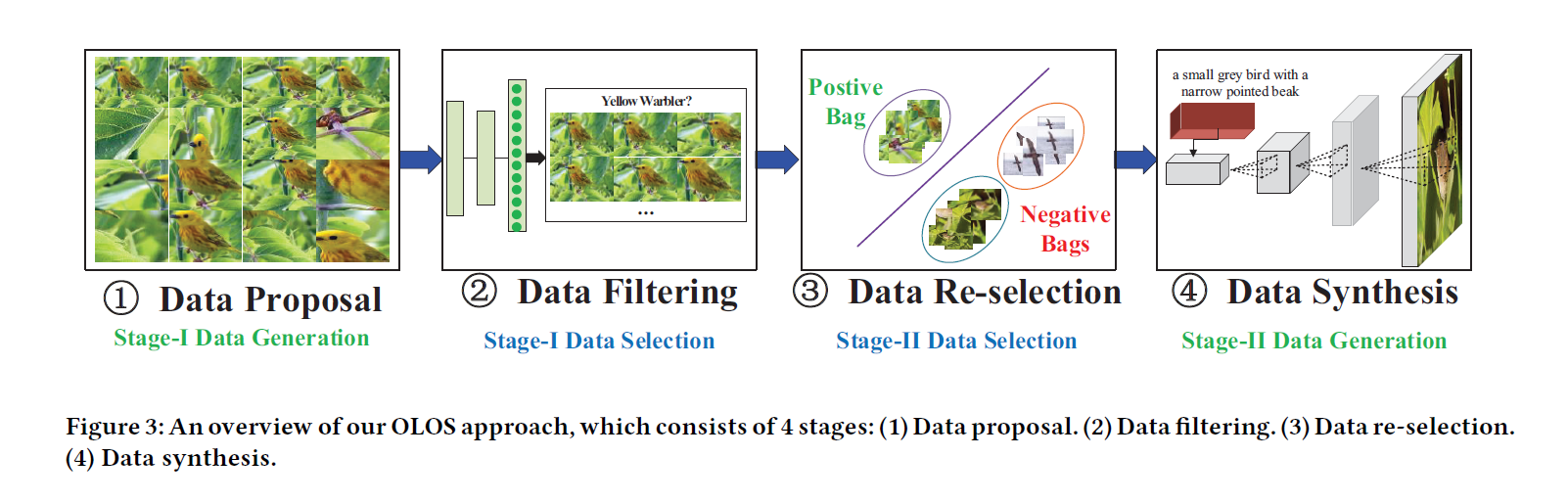
结构
结构图可知道,作者分为了四个步骤,我们分别来看一下。
Data Proposal
这一步作者是想,这一张训练样本怎么在其本身做个扩充呢。我们最常用的方法是 RandomCrop , 作者做的 是用 Selective search 来生成一些与图片中 object 相关的 image patch。
selective search 在目标检测中经常用到,先把图片分成许多小块,寻找具有相似区域(颜色,纹理等)的进行合并,然后提取的 proposal 便是合并的 外切矩形。
我这里放了一张效果图:
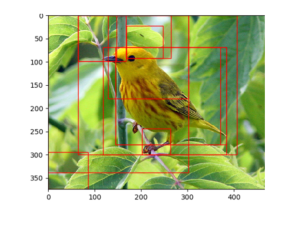
可以看到,不同于 randomcrop , ss 生成的区域是无固定尺寸大小的。
经过 ss ,作者认为就得到 多尺度,多视角的鸟的扩充样本
Data Filtering
这一步是对 ss 生成的 patch 进行过滤,去掉只包含背景的 patch 块。
步骤:
- 仅有单样本做训练 CNN ,记为 模型 M1
- 然后 M1 对这些 patch 块进行分类,如果正确,则保留。
这样就能过滤掉一些 仅有 background 的 image patch。
Data Re-selection
上一步的过滤实际上并不能完全去除
如下图:

标记为 × 号的图片,本来应该是去掉。但是由于 CNN 在这个单样本训练的过程中,反而有时对背景太过敏感。使得全是背景的图片也可能会被分类正确。那我们怎么去掉它呢???

作者引入了一个叫做 多示例学习的东西。他把所有的待 re-selection 的样本记为 positive Bags, 其余类的样本统统为 Negative Bags。 而 positive Bags 要求至少包含一个 正样本(包含鸟的 patch 就可以称为正样本, 只有背景的叫做负样本)。通过训练 用多示例学习的 SVM,就能把Positive Bags 里边的 负样本去掉。N 个类,要训练 N-1 个 SVM。
这一块大体思想是这样,具体细节作者没介绍,网上对多示例学习内容十分少。所以具体原理不再介绍
DCGAN
最后一步,保留剩下的 patch 块,训练 DCGAN,同时引入文本描述 (eg.鸟的头是黄色的) 作为 条件(条件-DCGAN)。
实验

上边是只用 一张样本训练的 GAN,下边是 用了前边三个操作后的。

这个表对不同阶段进行实验。结果要高于 Baseline 2 % 。